본 글은 TensorRT documentation과 NVATIC Webinar 발표자료를 정리한 글입니다.
TensorRT는 딥러닝 프레임워크로 구현된 모델을 NVIDIA hardware에서 쉽게 가속화하기위한 SDK입니다.
TensorRT 작동 방식
TensorRT는 2단계로 실행이 됩니다. 먼저 Build Phase 단계에서는 모델을 정의하고 target GPU에 맞게 모델을 최적화합니다. Run Phase 에서 최적화한 모델을 실행합니다. 각각 더 자세히 살펴보겠습니다.
1. The Build Phase
Build phase에서는 inference를 위해 최적화된 static graph (Engine)을 생성합니다. Engine을 생성하기 위해서는 모델을 정의하고 (Network Definition), builder를 위한 configuration을 설정하고, 해당 config를 바탕으로 builder를 호출하는 과정을 거쳐야합니다.
Network Definition을 하는 가장 쉬운 방법은 특정 framework로 구현된 모델을 ONNX format으로 export한 후에, TensorRT’s ONNX parser를 사용해서 모델을 정의할 수 있습니다. 이외에도 TensorRT’s Layer 혹은 TensorRT interface를 사용해서 모델을 직접 구현할 수도 있습니다.
그 후에 Configuration을 통해 TensorRT가 모델을 어떤 방식으로 최적화할지 결정할 수 있습니다. 모델의 weights 혹은 activations의 precision을 선택하거나, memory와 runtime execution speed 사이의 tradeoff를 조정하거나, CUDA kernel을 선택할 수 있습니다.
모델을 정의하고 configuration을 설정한 후에 builder를 실행하면 builder는 dead computation을 제거하거나, constant folding 혹은 GPU에서 효율적으로 실행하기 위해 연산 순서를 변경하거나 합치는 작업을 수행해서 Engine을 생성합니다. 앞서 말한 작업 외에도 configuration에 따라 precision을 낮추거나 quantziation을 수행합니다. 좀 더 구체적으로 살펴보겠습니다.
1.1. Kernel Fusion
Builder가 하는 일 중 하나는 kernel fusion입니다. GPU에서 실행되는 함수를 kernel이라고 하는데, kernel을 실행하면 global memory에서 데이터를 로드해서 연산을 수행하고 그 결과를 다시 global memory에 저장합니다. 이렇게 kernel 1개당 최소 2번의 global memory access를 수행하기 때문에, 여러 kernel을 1개로 합칠 수 있다면 memory에 접근하는 횟수가 줄어서 inference 속도가 향상이 됩니다.
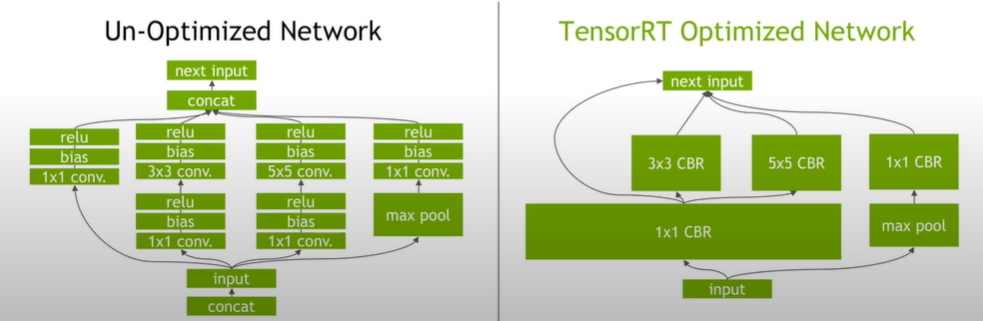
Kernel fusion에는 Vertical fusion과 Horizontal fusion이 있습니다. Vertical fusion은 sequential kernel을 합쳐서 1개의 kernel로 만듭니다. 예를들어 위의 그림에서 Un-optimized Network 부분에 위에서 2번째 줄을 보시면 conv-bias-relu 연산이 있습니다. 오른쪽 TensorRT Optimized Network 부분을 보면, 이 3개의 kernel을 1개의 kernel로 합쳐서 3x3 CBR (Conv-Bias-Relu), 5x5 CBR, 1x1 CBR로 변환을 합니다.
Horizontal fusion 같은 종류의 kernel인데 다른 weight를 사용하는 경우에, 해당 kernel을 1개로 합쳐서 병렬적으로 실행되도록 만드는 방법입니다. 예를들어 Un-optimized Network 부분에 위에서 3번째 줄에서 1x1 conv - bias - relu kernel이 2개씩 있는데, 해당 kernel을 Vertical fusion을 하면 같은 종류의 1x1 CBR kernel이 생성됩니다. 1x1 CBR kernel을 중복해서 생성하지 않고, 1개만 생성한 후에 각각 다른 weight를 사용하는 방식으로 변환을 합니다.
1.2. Kernel Autotuning
TensorRT에는 자주 사용되는 연산을 low-level로 구현한 알고리즘들이 있습니다. 자주 사용되는 연산이 있으면 해당 연산의 파라미터와 target platform에 최적화된 kernel을 선택해서 기존 kernel을 대체합니다. 예를들어 convolution의 경우 batch size, filter size, input data size, target platform에 따라 다른 최적화된 kernel을 사용합니다.
1.3. Precision Calibration
네트워크는 보통 FP32로 학습이 되는데 inference 단계에서는 backpropagation 과정이 없어서 precision의 영향을 비교적 덜 받습니다. 그래서 precision을 설정하고 calibration을 통해 range를 결정한 후에 weight 혹은 activation의 precision을 낮추는 과정을 수행합니다. Precision이 낮아지면 모델 크기, memory 사용량, latency가 줄어들고 throughput이 향상됩니다.
TensorRT는 Symmetric uniform quantization을 이용한 INT8 quantization을 지원합니다. Network에 quantization을 적용한 Quantized Network는 implicit 혹은 explicit 형태로 나타낼 수 있습다. Implicit 형태로 나타내게 되면, 모델의 performance를 가속화할 수 있는 layer에 TensorRT가 INT8 quantization을 적용합니다. 그래서 유저입장에서는 구체적으로 quantization을 적용할 layer를 선택하지 못하게 됩니다.
Explicit 형태로 나타내는 방식은 유저가 quantization을 적용하기 원하는 layer에 IQuantizeLayer와 IDequantizeLayer를 사용하면 됩니다. 이런 방식을 fake quantization이라고 하는데, quantization -> INT8 multiplication -> dequantization 단계로 연산이 수행이 돼서, 일반적으로는 full precision model보다 inference 속도 측면에서 느릴 가능성이 있습니다. TensorRT에서는 위에 3단계를 하나의 node로 fuse합니다.
Post-Training Quantization을 적용할 때 scale 값을 결정하기 위해서 calibration 단계가 필요합니다. 이 단계에서는 quantization을 수행할 때 발생하는 두 가지 오류 - Discretization error: quantized value의 표현 범위를 넓힐수록 quantization resolution이 줄어들어서 발생하는 오류, truncation error: 표현 범위를 넘어선 값을 clamp해서 발생하는 오류 - 사이에 균형을 맞추는 것이 중요합니다.
1.4. Dynamic Tensor Memory & Multi-Stream Execution
각 tensor의 duration을 파악해서, 해당 tensor가 사용되는 동안에만 tensor를 memory에 할당합니다. 이를 통해 memory footprint를 줄이고 memory 재사용량을 증가시킵니다.
모델 하나를 여러 user에 배포를 할 때 여러 입력을 받아야 하는데, 이때 TensorRT의 multi-stream을 사용해서 multiple input stream을 병렬적으로 처리할 수 있습니다.
Comments powered by Disqus.